


SPV是“Simplified Payment Verification”(简单支付验证)的缩写。中本聪论文简要地提及了这一概念,指出:不运行完全节点也可验证支付,用户只需要保存所有的block header就可以了。
随着数字货币交易量不断扩大,存储交易信息的区块也逐渐庞大,而中本聪在比特币网络中所设定的1M区块限制,也就导致了一个区块中所能容纳的交易数量极少,交易速度受限,也就导致目前众多人关于区块链扩容问题提出各种不同的方案。
扩容势必导致区块内存扩大,对于一些小型节点,在验证交易支付时,需要将整个区块链数据保存在本地硬件上,数据随着交易扩充而逐步扩大,占据大量存储空间以及牺牲高额带宽资源,为了验证一笔交易的真实性而保存整个网络信息,这是不合理的操作规则。
Merkle树在SPV 中充当什么角色?
SPV属于区块链当中支付验证体系中的一种,是为了适应简便、快速支付的验证手段,它不需要下载新区块所有数据,只需要保存区块头部数据,这些数据保存在默克尔树当中。
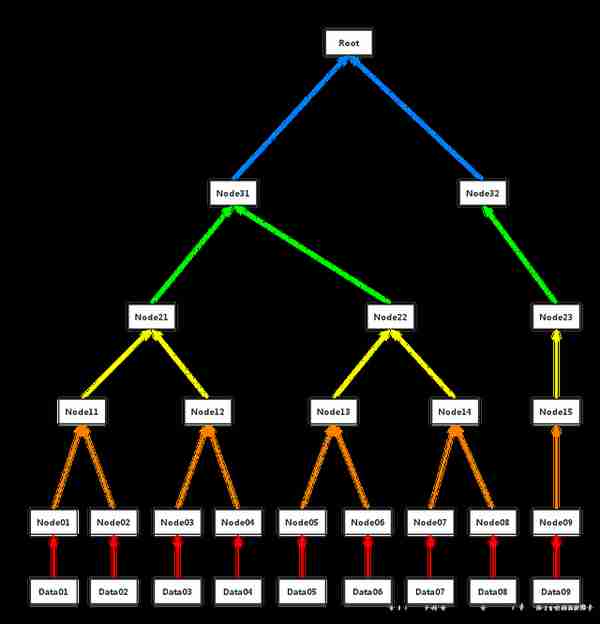
Merkle树
Merkle树是一种哈希二叉树,它是一种用作快速归纳和校验大规模数据完整性的数据结构。这种二叉树包含加密哈希值。默克尔树底部的树叶是我们的交易数据,而每一个父节点是两个子节点哈希值之和的哈希值。
也就是说,默克尔树的叶子节点保存着交易数据信息,而节点之间通过哈希计算得到父节点哈希值,通过一层层往上层计算,最终会形成根节点,而这样的“信息树”构成了整个网络的交易数据,由于节点都是哈希值,易于存储以及验证。
SPV验证原理
验证流程:
1、 计算待验证支付的交易哈希值。
2、 节点从网络中获取所有区块头信息保存到本地。
3、 节点从区块链获取待验证支付对于的默克尔树哈希认证路径。
4、 根据哈希认证数据,与保存在本地的默克尔树比较,定位到包含本次交易的区块。
5、 验证该区块头信息包含在已知最长链当中。
6、 根据区块头位置,确认已经确认的确认数(比特币网络确认一笔交易需要至少6次确认)。
简单来讲,就是比特币网络里的节点在打包一个区块的时候,会对区块里所有的交易进行验证,并且,一个交易还会得到6至7次的确认来确保交易最后的完成。正是如此,在使用简单支付验证时,只要判断出一个交易在主链上的某个区块里出现过,则可以证明该交易之前已被验证过。
SPV属于区块链支付验证,而不是交易验证,它只负责判断该交易是否已经得到区块链当中的节点共识验证,并得到多少次确认。
SPV支付验证优缺点
使用SPV简单支付验证,可以节省一大笔存储空间,无论未来交易量有多大,它的block header保存的数据(哈希值)都是固定大小,80个字节,按照每小时6个的出块速度,每年产出52560个区块。当只保存block header时,每年新增的存储需求约为4兆字节,100年后累计的存储需求仅为400兆,即便是最普通的终端硬件设备,也有将数据保存在本地的能力。
当然,这种简单的支付验证也带来一定的弊端,攻击者在P2P网络当中交易,形成与该交易相同的输入、输出新交易,出现双花问题,也即是“可锻性攻击”。 “交易可锻性”指的是,比特币支付交易发出后、确认前可被修改(准确说是被伪造复制),用户签名过的信息不能更改。
为什么会出现这种双花问题?这需要回到整个交易流程来看,在椭圆曲线算法ECDSA当中,修改某个字节签名也能使得签名验证成功。两个不同的ID号进行交易(在规定时间内),第三方(支付方)由于发现两笔相同交易而判断交易失败,此时用户修改相应签名信息(不包含主要签名信息),形成两笔不一样的交易,第三方看到交易失败而再次交易(事实上已经支付过了),则用户能产生两笔交易(收到两份比特币)。
从交易信息发出到最终确认通常有约10分钟的时间,事实上,伪造的交易信息产生于正品交易信息之后。由于挖矿程序的确认过程是一个随机的过程,后产生的伪造的交易信息可能首先通过确认,这时正品交易信息反而被认为是重复支付被丢弃。发送方看到自己发的正品交易没通过校验,误以为支付失败(其实已成功支付),再次发送交易,支付方就支付了多余的币。
风险与效率权衡
在交易过程中,如果矿工声称存在这条交易,但其实并没有,要想达成,它就必须伪造更多的交易,使得这些交易层层哈希以后得到的值,与你下载的区块头里的哈希值是一样的。但由于哈希的技术特性,改变后的数据要想和原始数据得出一样的哈希值的可能性微乎其微。
理论上这种“可锻性攻击”风险会出现,但事实上要达成这种条件概率较低,并且在主流的交易平台都有着防范措施,只对于一些轻钱包设定的场景下,会出现一定隐患,这就需要使用者在效率与风险中权衡利弊。
SPV有其自身绝对优势,简便、高效的验证方法,相信后续通过对机制里利益的平衡,利用技术手段避免风险出现,这种验证方式会得到更多应用场景,毕竟,没有人会想把与自身不相关的交易数据也下载到本地。
 上一篇
上一篇



